| The Relational Data Model |
The Relational Data Model has the relation at its heart, but then a whole
series of rules governing keys, relationships, joins, functional dependencies,
transitive dependencies, multi-valued dependencies, and modification anomalies.
The Relation is the basic element in a relational data model.
A relation is subject to the following rules:
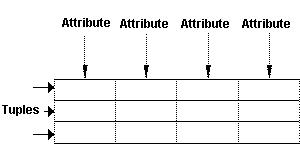
- Relation (file, table) is a two-dimensional table.
- Attribute (i.e. field or data item) is a column in the table.
- Each column in the table has a unique name within that table.
- Each column is homogeneous. Thus the entries in any column are all of
the same type (e.g. age, name, employee-number, etc).
- Each column has a domain, the set of
possible values that can appear in that column.
- A Tuple (i.e. record) is a row in the table.
- The order of the rows and columns is not important.
- Values of a row all relate to some thing or portion of a thing.
- Repeating groups (collections of logically related attributes that occur
multiple times within one record occurrence) are not allowed.
- Duplicate rows are not allowed (candidate keys are designed to prevent
this).
- Cells must be single-valued (but can be variable length). Single valued
means the following:
- Cannot contain multiple values such as 'A1,B2,C3'.
- Cannot contain combined values such as 'ABC-XYZ' where 'ABC' means
one thing and 'XYZ' another.
A relation may be expressed using the notation R(A,B,C, ...)
where:
- R = the name of the relation.
- (A,B,C, ...) = the attributes within the relation.
- A = the attribute(s) which form the primary key.
- A simple key contains a single attribute.
- A composite key is a key that contains more than one attribute.
- A candidate key is an attribute (or
set of attributes) that uniquely identifies a row. A candidate key must
possess the following properties:
- Unique identification - For every row the value of the key must
uniquely identify that row.
- Non redundancy - No attribute in the key can be discarded without
destroying the property of unique identification.
- A primary key is the candidate key which is selected as the
principal unique identifier. Every relation must contain a primary key. The
primary key is usually the key selected to identify a row when the database
is physically implemented. For example, a part number is selected instead of
a part description.
- A superkey is any set of attributes that uniquely identifies a
row. A superkey differs from a candidate key in that it does not require the
non redundancy property.
- A foreign key is an attribute (or set
of attributes) that appears (usually) as a non key attribute in one relation
and as a primary key attribute in another relation. I say usually
because it is possible for a foreign key to also be the whole or part of a
primary key:
- A many-to-many relationship can only be implemented by introducing
an intersection or link table which then becomes the child in two
one-to-many relationships. The intersection table therefore has a
foreign key for each of its parents, and its primary key is a composite
of both foreign keys.
- A one-to-one relationship requires that the child table has no more
than one occurrence for each parent, which can only be enforced by
letting the foreign key also serve as the primary key.
- A semantic or natural key is a
key for which the possible values have an obvious meaning to the user or the
data. For example, a semantic primary key for a COUNTRY entity might contain
the value 'USA' for the occurrence describing the United States of America.
The value 'USA' has meaning to the user.
- A technical or surrogate or
artificial key is a key for which the possible values have no obvious
meaning to the user or the data. These are used instead of semantic keys for
any of the following reasons:
- When the value in a semantic key is likely to be changed by the
user, or can have duplicates. For example, on a PERSON table it is
unwise to use PERSON_NAME as the key as it is possible to have more than
one person with the same name, or the name may change such as through
marriage.
- When none of the existing attributes can be used to guarantee
uniqueness. In this case adding an attribute whose value is generated by
the system, e.g from a sequence of numbers, is the only way to provide a
unique value. Typical examples would be ORDER_ID and INVOICE_ID. The
value '12345' has no meaning to the user as it conveys nothing about the
entity to which it relates.
- A key functionally determines the other attributes in the row, thus it
is always a determinant.
- Note that the term 'key' in most DBMS engines is implemented as an index
which does not allow duplicate entries.
|