| Determinat And Dependent |
The terms determinant and dependent can be described as follows:
- The expression X
 Y
means 'if I know the value of X, then I can obtain the value of Y' (in a
table or somewhere). Y
means 'if I know the value of X, then I can obtain the value of Y' (in a
table or somewhere).
- In the expression XY,
X is the determinant and Y is the dependent attribute.
- The value X determines the value of Y.
- The value Y depends on the value of X.
A functional dependency can be described as follows:
- An attribute is functionally dependent if its value is determined by
another attribute.
- That is, if we know the value of one (or several) data items, then we
can find the value of another (or several).
- Functional dependencies are expressed as XY,
where X is the determinant and Y is the functionally dependent attribute.
- If A(B,C)
then AB
and AC.
- If (A,B)C,
then it is not necessarily true that AC
and BC.
- If AB
and BA,
then A and B are in a 1-1 relationship.
- If AB
then for A there can only ever be one value for B.
A transitive dependency can be described as follows:
- An attribute is transitively dependent if its value is determined by
another attribute which is not a key.
- If XY
and X is not a key then this is a transitive dependency.
- A transitive dependency exists when ABC
but NOT AC.
A multi-valued dependency can be described as follows:
- A table involves a multi-valued dependency if it may contain multiple
values for an entity.
- A multi-valued dependency may arise as a result of enforcing 1st normal
form.
- X
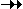 Y,
ie X multi-determines Y, when for each value of X we can have more than one
value of Y. Y,
ie X multi-determines Y, when for each value of X we can have more than one
value of Y.
- If AB
and AC
then we have a single attribute A which multi-determines two other
independent attributes, B and C.
- If A(B,C)
then we have an attribute A which multi-determines a set of associated
attributes, B and C.
A join dependency can be described as follows:
- If a table can be decomposed into three or more smaller tables, it must
be capable of being joined again on common keys to form the original table.
A major objective of data normalisation is to avoid modification anomalies.
These come in two flavours:
- An insertion anomaly is a failure to place information about a
new database entry into all the places in the database where information
about that new entry needs to be stored. In a properly normalized database,
information about a new entry needs to be inserted into only one place in
the database. In an inadequately normalized database, information about a
new entry may need to be inserted into more than one place, and, human
fallibility being what it is, some of the needed additional insertions may
be missed.
- A deletion anomaly is a failure to remove information about an
existing database entry when it is time to remove that entry. In a properly
normalized database, information about an old, to-be-gotten-rid-of entry
needs to be deleted from only one place in the database. In an inadequately
normalized database, information about that old entry may need to be deleted
from more than one place, and, human fallibility being what it is, some of
the needed additional deletions may be missed.
An update of a database involves modifications that may be additions,
deletions, or both. Thus 'update anomalies' can be either of the kinds of
anomalies discussed above.
All three kinds of anomalies are highly undesirable, since their occurrence
constitutes corruption of the database. Properly normalised databases are much
less susceptible to corruption than are unnormalised databases.
|


